Note in Swedish: Jag hoppas läsaren ursäktar att jag skriver på engelska då och då.
This will be a brief introduction to using the statistics software R for biologists who want to do some of their data analysis in R. There are plenty of introductions to R (see here and here, for example; these are just a couple of intros that make some good points), but I’d like to show a few things that I wish somebody would’ve told me when I started learning R. As always with R, if you need any help, just type a question into a search engine. Often someone else asked first.
Caveat lector: I don’t pretend to be an expert, just another user. Since R speaks to you through a text based interface, some code will be involved — but if you really want to learn computer programming, R is probably not the best place to start, and I’m certainly not the best teacher. However, while using R, you will naturally want to write scripts, and practice a humble form of literary programming.
1. Why R?
What? R is an environment for computation and graphics. R is free software, meaning that you can distribute, copy, and modify it. It is development is a big collaborative effort. The name referes to the fact that R started as a free implementation of S.
Why? R is very common among scientists (at least biologists and statisticians). It is a full-fledged statistiscs software, and it is easily extensible, meaning that there are tons of useful (as well as less useful) packages for solving different problems. This introduction will start with base R, but will liberally use a bunch of great package.
R is usually not the most efficient way to do things in terms of computation time. If you have huge datasets (i.e. things that don’t fit in the RAM of your computer) you might have to turn to something else. R is, however, supremely flexible, and often very convenient. It takes commands from a command prompt or a script file, and outputs text, files, and graphics when told to.
R comes with automated installers for lots of platforms, and installation is pretty easy. If you want a nice graphical interface, I suggest Rstudio. R comes with its own graphical user interface, but I find it annoying. I usually work with R in a terminal window, like this: At the shell of a unix terminal, just write ”R”. A legal disclaimer and a friendly ”>” greets you. You are now interacting with R.
If you use one of the graphical interfaces, you will see the same things, but also a few other windows for editing script files, showing graphs etc.
2. Getting data into R
Say you have your data in a spreadsheet file. How do you get it into R? The easiest way is probably to export you spreadsheet tables to comma separated values (csv). (Just choose Save as… and select csv format in your favourite spreadsheet software). For this example, I use some made up data stored in data.csv. The read.csv() function reads csv files (duh). read.table() will read any tabulated data.
If you want to play along with the instructions, you can download comb_gnome_data.csv. If you work with the default R interface or R on the command line, you will have to put the file in your R working directory. In the R graphical interface, you can set and get the working directory under Misc (Mac) or File (Windows) in the menu bar.
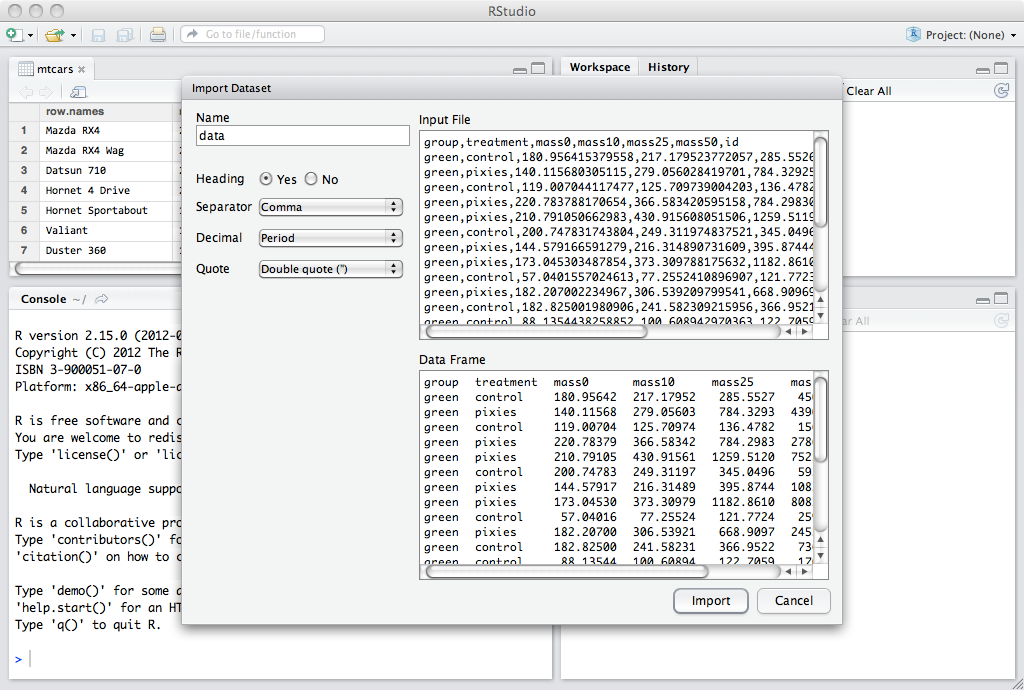
If you work with Rstudio, you can press the Import dataset button to open an import guide, and then skip over most of this section. Rstudio is nice.
You run a function in R by writing its name followed by parentheses. Any parameters you pass to the function will be given in the parenthesis in a parameter=”value” format, like so.
data <- read.csv(file="comb_gnome_data.csv", header=T)
The arguments can either be given with their proper name, or in the default order. The arguments and output of any function are described in the help file — to read it, enter a question mark and the name of the function:
?read.csv
Above, we’re telling R to run read.csv() with the file ”comb_gnome_data.csv”, and the option header set to true. The arrow ”<-" means assignment, telling R to save the output of read.csv() to the variable called "data". You can recall it by simply giving the name of the variable, and R will print the whole table.
data
If your table is huge, this might not be helpful. Use head() and tail() to see the beginning and end of the table. dim() tells you how many rows and colums you have. This table format is called a data.frame, and is the basis of many operations in R.
head(data)
group treatment mass0 mass10 mass25 mass50 id 1 green control 180.9564 217.1795 285.5527 450.6075 1 2 green pixies 140.1157 279.0560 784.3293 4390.4606 2 3 green control 119.0070 125.7097 136.4782 156.5143 3 4 green pixies 220.7838 366.5834 784.2983 2786.0915 4 5 green pixies 210.7911 430.9156 1259.5120 7525.7961 5 6 green control 200.7478 249.3120 345.0496 593.0786 6
These data are of course fictive — imagine they are measurements of mass at different time points (0, 10, 25 and 50 imaginary time units) of pink and green comb gnomes in the presence or absence of pixietails.
dim(data)
[1] 99 7
In this case, we have 99 rows and 7 columns.
Before reading an unkown file, it is a good idea to inspect it and make sure things are in order. Also, if you get strange error messages from read.csv() or read.table(), it’s usually something easy, like using the wrong separator. Open it in your favourite text editor and check what the separator is (could be comma, tab, a space, or a semicolon, perhaps). R will also assume that all rows have an equal number of entries, for example.
A special note about empty cells: R has a special code — NA — for missing values. Sometimes you have another symbol for missing values, such as ”-”. You can tell R this with the na.strings parameter.
other.data <- read.table(file="other_data.txt", sep="\t", header=F, dec=",", na.strings=c("-", "NA", "omgwtf"))
Here, the data file uses tab as separator, has no header, uses comma as decimal separator (hello Swedish users), and ”-”, ”NA” or ”omgwtf” for missing values.
A final thing on entering data: R uses different formats for numbers, strings of characters, and factors (think: categories). R will recognise your numbers as numbers, but if you enter text, R will default to factors. Sometimes, say when you use a sample id that contains letters, you’d prefer text columns to be ”character”. To do that, give the parameter stringsAsFactors=F. If you don’t get this right when entering the file, don’t worry, you can change type later.
(For more details, see a comprehensive input manual here.)
3. Getting, setting and subsetting
So you have entered your data into a data frame and had a look at it with dim(), and head(). You will probably want do display some more.
Too look at one of the columns of a data frame, you write the name after a $ sign, and R will print it. head() works here as well, printing only the beginning of this particular column.
data$id head(data$id)
To summarise the values, getting a few descriptive statistics from a numeric column, use summary().
summary(data$mass0)
Min. 1st Qu. Median Mean 3rd Qu. Max. 11.93 87.43 130.80 128.10 168.10 240.00
table() will count the values, and is useful for categories (i.e. factors):
table(data$group)
green pink 50 49
When you want to calculate stuff, just write a formula. You can use variable names, and if the name refers to a whole column of a data frame, R will either perform the calculation on every value, or (for certain functions that operate on vectors) use the entire column for some calculation. The output will be printed, or can be assigned to a variable. The square of the mass of each individual at time zero:
data$mass0^2
There are a bunch of useful functions that operate on columns (or in general vectors) — for example sum, mean, median, and standard deviation:
sum(data$mass0) mean(data$mass0) median(data$mass0) sd(data$mass0)
To change the value of a column, or add a column, you can simply assign to it with ”<-", and perform any algebraic operation. Here, we form the difference between mass at time 50 and mass at time 0 and call it "growth".
data$growth <- data$mass50 – data$mass0
There are several ways to take subsets of you data. First, the bracket operator treats your data frame as a table, getting cells by two indices: data[1,2] will give you the cell in the first row, and the second column.
The second column:
data[,2]
The third row:
data[3,]
The third row of the second column:
data[3,2]
c() is for concatenation. It will give you a vector of several values, and it can be used for example when getting multiple columns:
Column 1 and 3:
data[, c(1,3)]
The columns called "mass0" and "id":
data[, c("mass0", "id")]
Usually, it is a good idea to refer to columns by name when possible. If you refer to them by numbers, and later add a column to the data file, your code might do something different than you expect.
You can also use the subset function. The first argument is the name of your data frame, and the second some logical condition for the rows you want. Here, for example, we select all rows where mass at time 0 is strictly below 10.
subset(data, mass0 < 10)
You can combine several conditions with "&" (and) and "|" (or):
subset(data, mass0 < 100 & mass50 > 500)
group treatment mass0 mass10 mass25 mass50 id 50 green pixies 80.52379 127.4023 253.5461 798.3436 50 55 pink pixies 95.36059 142.0190 258.1147 698.6453 55 72 pink pixies 87.72898 139.0989 277.7121 879.1167 72 77 pink pixies 97.04335 145.6220 267.6816 738.3653 77 82 pink pixies 87.12299 142.4427 297.7841 1017.8186 82 97 pink pixies 79.43528 115.0147 200.3843 505.4915 97
That was a quick introduction to handling data frames. In the next installment, we’ll make some graphs. R has some really nice plotting capabilites. Once we’ve gotten the numbers into a data frame, plotting them turns out to be quite easy.
Please feel free to post questions and comments if you have any. Cheers!

Pingback: Slides from my R intro seminar | There is grandeur in this view of life
There is some error in part 3:getting,setting and subsetting.
First, To look at…
Second, summary(data$mass) it should be summary(data$mass0)
Thank you very much!
Pingback: Using R: common errors in table import | There is grandeur in this view of life
Pingback: Using R: common errors in table import ← Patient 2 Earn
I have one question about importing data into R as I’m new to this software and will need to analyse some data soon. I view my data in an excel spreadsheet and it looks fine although there are many blank cells. I know this represents ‘Nodata’. However when I read it into R as a text file the blank cells that were in position in excel disappear, as rows are compressed to the left hand side (ie. Removing blanks). This results in many values being under the wrong heading. Can you help I would appreciate it so much? I have been struggling with this for ages Thanks
Hi! It’s difficult to know without seeing your file and what happens with it, but my first guess would be check the field delimiter (the sep= argument), and check that it matches the actual delimiter in the file. Mismatches could possibly cause strange problems.
Unfortunately, https://people.ifm.liu.se/marjon/comb_gnome_data.csv seems to have zero bytes!
I’d like to try the examples though, if this can be corrected.
Thanks
Ah, sorry about that. I couldn’t find the actual file, but I did find the script that generates the file, so here is a new iteration:
https://github.com/mrtnj/rstuff/blob/master/comb_gnome_data.csv
I’ll update the post too.
Thanks for your interest! This tutorial is pretty out of date by now, but I hope it’s of some use.