Någon gång i somras publicerade Cahill & co (2013) en vetenskaplig artikel om hur att äta eller inte äta frukost samt att äta sent på kvällen påverkar risken för kranskärlssjukdom. Ja, jag skriver ”påverkar”, för orsakssamband är precis det intressanta här. Även om författarna är duktiga forskare och medvetna om att association inte nödvändigtvis betyder klara orsakssamband, så är det vad vi vill veta. Inte om människor som tenderar att äta sent på kvällen sådär i allmänhet också tenderar att bli sjuka, utan om vi ska låta bli att äta sent på kvällen för att inte bli sjuka.
Men som alla vet är det där med orsak och verkan inte helt lätt — och det här var alltså en epidemiologisk observationsstudie där är det kan vara synnerligen knivigt. Men vad ska en göra då? Folk som slumpvis delas upp i grupper och tilldelas olika kost kan ju bara tänkas stå ut med det en kortare tid, så för att få veta något långtidseffekter på människor finns det inget annat sätt.
Jag tänker inte skriva så mycket om själva artikeln utan ta den som exempel på att det finns minst tre viktiga typer av osäkerhet som alla som analyserar och tolkar resultaten på något sätt behöver förhålla sig till. Artikeln, den här sammanfattningen, DN och Expressen gör det i olika grad och olika framgångsrikt.
1. Modellerad osäkerhet i skattningarna.
Den här typen av nog lättast att hantera — en statistisk metod värd namnet, oavsett allt annat, ger alltid någon sorts uppskattning av osäkerhet. Ibland uttrycks den i form av en sannolikhet men i det här fallet som ett intervall. Intervallet visar vilka värden som i någon mån är förenliga med data. I artikelns sammanfattning står intervallet 1,06-1,53 för riskkvoten som jämför de som äter frukost och inte — alltså en förhöjd risk på mellan 6% och 53%. Varken Medpage Today eller svenska tidningar uppger något annat än punktskattningen 27%. På ett sätt är det begripligt, för vad ska vi göra med intervallet? Konstatera att osäkerheten är stor, att 53% är en extremt stor riskökning men att 6% fortfarande är en hel del?
Å andra sidan, när osäkerheten är så här stor är det fånigt och hyfsat vilseledande att bara skriva 27% som om det vore en säker siffra. En mening om statistisk osäkerhet skulle nog gjort mer nytta för DN:s läsare än en om vad resultaten betyder för den diet som för tillfället är på modet. (Obs: Lita aldrig på bloggare i kostfrågor. Inte mig heller.) Det finns fler exempel, så klart. Härförleden skrev jag om en artikel om inflammationshämmande antikroppar som rapporterade en skillnad som mycket väl skulle kunna vara noll som om den vore ett starkt överraskande resultat. Eller ta Aftonbladets artiklar om sexuella vanor i somras som rapporterade ett gäng medelvärden men berättade väldigt lite om variationen inom grupper.
2. Osäkerhet som har med studiens upplägg att göra.
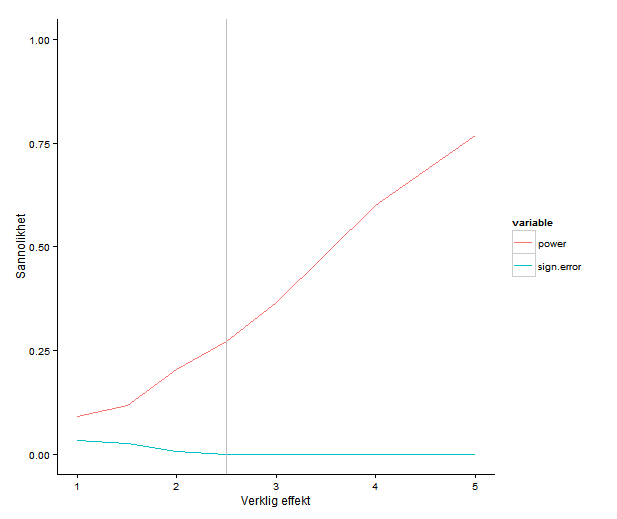
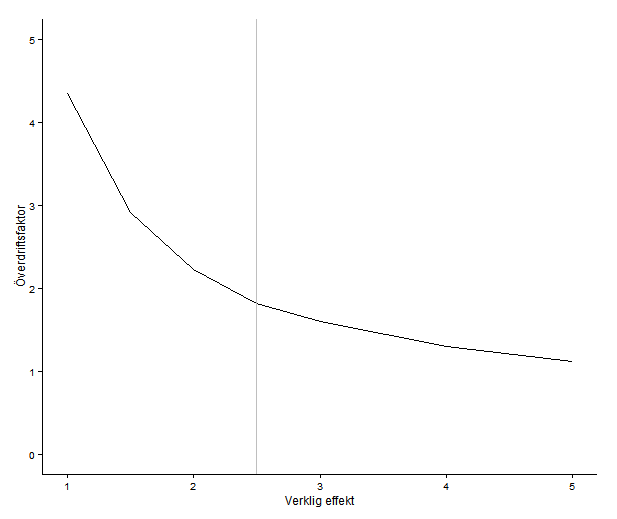
Här blir det genast svårare. Tyvärr räcker det inte alltid att titta på resultat och uppskattad osäkerhet för att veta om resultatet är trovärdigt. Ibland behöver en analysera studiens design och utförande. Kan den verkligen besvara den fråga den är satt att besvara? En del av analysen kan vara att beräkna styrka, vilket handlar om ifall urvalet är stort nog och variationen liten nog för att det ska gå att detektera en effekt av rimlig storlek. Styrkeberäkningar kräver alltså att vi gör antaganden om vad det är vi väntar oss hitta och vad som är rimligt — och helst att vi tänker till i förhand.
Det finns flera problem med att försöka dra slutsatser från ett för litet material: en kan missa effekter som finns där eftersom att de drunknar i bruset, men vad som är ännu värre: de effekter som faktiskt är stora nog att märkas kommer ofta vara överskattningar och orimligt stora. Den här artikeln är i alla fall inget litet utgångsmaterial: omkring 27000 individer totalt, men när det kommer till att äta sent på natten är det bara 313 individer kvar som har den vanan.
Studien visade också att en sen måltid eller nattlig räd i kylskåpet är ännu värre för hjärthälsan än att hoppa över frukosten. Männen som uppgav att de åt efter att ha gått till sängs löpte 55 procents högre risk för hjärtsjukdom. (DN)
När jag läste det här tänkte jag ungefär: Skojar ni? 30% är stort nog, men 55%! Men den uppfattning att baserades helt på mitt eget huvud och uppfattningen att hälsa är komplicerat och att effekter borde vara små. Men lita inte på mig! Poängen är att vad som är rimligt går att studera. Om en tittar på ett par metaanalyser (alltså en studie som sammanställer resultaten många tidigare studier) av risken för kranskärlssjukdom finns bland annat: diabetes 1,9 (för män; för kvinnor 2,6; Lee & al 2000); passiv rökning 1,2-1,3 (He & al 1999) och 0,8 för de som äter mycket frukt och grönsaker (He & al 2007 ). Så frukost eller ej skulle vara ungefär jämförbart med passiv rökning; att äta sent värre, men inte lika illa som diabetes. Det kanske är rimligt; vad vet jag. Om 313 individer i högriskgruppen ger tillräcklig styrka för att trovärdigt kunna skatta lägre skillnader är inte lätt att veta när artikeln inte rapporterar någon formell styrkeanalys. Om inte är det stor risk att överskatta effekten.
Till studiens upplägg hör inte bara storleken utan frågan om systematiska fel. Fånigt exempel: den som vill uppskatta hur stor andel av Norrköpingsborna som håller på Vita hästen bör inte bara intervjua de som kommer ut från Himmelstalundshallen. En vanlig kritik mot olika typer av experimentell forskning på människor är att den använder folk som är WEIRD (”western, educated, and from industrialized, rich, and democratic countries … vita, välutbildade från industrialiserade, rika och demokratiska länder”) — kort och gott, det kan finnas skäl att ifrågasätta den frivilliga universitetsstudenten som modell för hela mänskligheten. Det finns en annan viktig del också, efter urvalet, nämligen förklaringsvariablerna (ovan: att äta frukost eller inte) och hur de hör ihop med andra variabler. Om en gör ett experiment går det ju att slumpvis tilldela försökspersoner att äta frukost eller inte äta frukost. Det kallas randomisering. Då kan en vara ganska säker på att isolera just effekten av frukost och inte en massa andra saker. Men i studien ovan är det ju inte fråga om slumpvis tilldelade frukostar och sena nätter, utan folks faktiska vanor. Det är ju möjligt och troligt att människor som hoppar över frukost också har andra vanor, som kanske inte är så hälsosamma, som påverkar deras risk för hjärtsjukdom. Och det för oss till den tredje typen av osäkerhet:
3. Osäkerhet om orsak och verkan.
Svårast. Jävligt svårt! Här är inte ens de lärde överens om hur en ska räkna alla gånger. Det finns i alla fall bra statistiska verktyg för att försöka hantera flera variabler som påverkar varandra: olika typer av statistiska modeller med olika sätt att ”justera för” variabler. För att fortsätta tanken från ovan: Författarna vill jämföra risken för hjärtsjukdom hos de som äter frukost och de som inte gör det, men det kan vara så att grupperna också skiljer sig på andra sätt som kan påverka risken för hjärtsjukdom: till exempel ålder och diet. Därför justerar de för demografi, diet och några livsstilsvariabler som de känner till om deltagarna. Det betyder att bygga en modell som inkluderar de variablerna förutom frukostvanor. Om modellen är bra så kan de uppskatta skillnaden mellan frukostätarna och frukosthopparna och ha viss kontroll på att den inte beror på de andra variablerna.
Men samtidigt går det inte att justera för vad som helst och hur som helst. I artikeln och i sammanfattningen jag länkade ovan står det att
The relationships between coronary heart disease and both skipping breakfast and eating late at night became nonsignificant after adjustment for potential mediators …
Författarna prövar alltså att justera för några ”potential mediators” i det här fallet är bland annat högt blodtryck. Att skillanden ”became nonsignificant” betyder att justeringen får den uppskattade skillnaden att krympa (så att det 95%-iga intervallet inte utesluter att effekten är noll). Vad betyder det? Det författarna menar med potentiellt medierande variabler är saker som orsakar hjärtsjukdom men som i sin tur skulle kunna påverkas av frukostvanor. Om ingen frukost ger högre blodtryck som ger högre risk för hjärtsjukdom borde uppskattningen av riskökningen mellan ingen frukost och frukost minska om vi justerar för blodtryck. De använder alltså justeringen som ett sätt att pröva om en del av skillnaden kan förklaras av högre blodtryck.
Men det gäller att hålla tungan rätt i munnen … Om en ska justera eller inte beror på orsakssambanden mellan variablerna. Om vi missar att justera för något som skiljer grupperna kan det ge helt fel resultat. Om vi justerar för något som är en följd av det vi är intresserade av riskerar vi att justera bort den intressanta effekten. Vilken uppskattning, ojusterad eller inte, som är den rätta beror på vad som är sant om fenomenet ifråga. Så, lite som att en behöver veta något om vilka effekter som är rimliga för att begripa effektstorlekar så måste vi redan veta något om orsak och verkan för att kunna resonera om det. (Pearl 2014)
Litteratur
Cahill & al (2013) Prospective Study of Breakfast Eating and Incident Coronary Heart Disease in a Cohort of Male US Health Professionals Circulation
He & al (1999) Passive Smoking and the Risk of Coronary Heart Disease — A Meta-Analysis of Epidemiologic Studies New England journal of medicine
He & al (2007) Increased consumption of fruit and vegetables is related to a reduced risk of coronary heart disease: meta-analysis of cohort studies Journal of human hypertension
Lee & al (2000) Impact of diabetes on coronary artery disease in women and men: a meta-analysis of prospective studies Diabetes care
Pearl (2013) Understanding Simpson’s Paradox. Förtryck på författarens webbsida