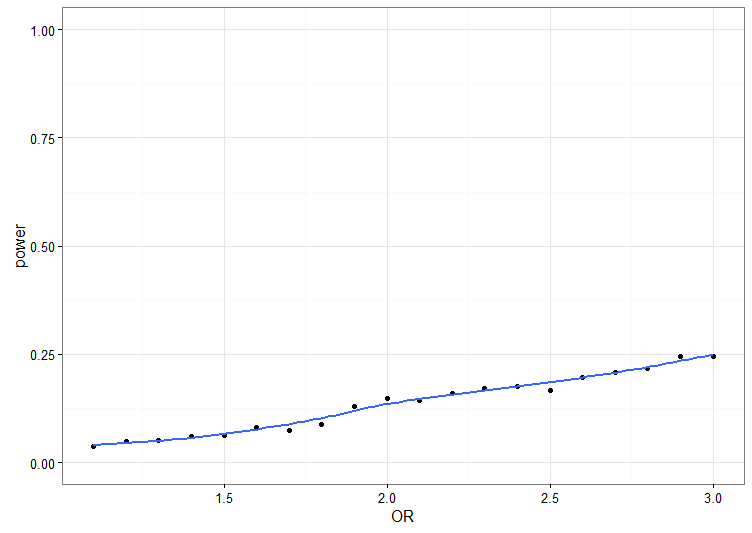
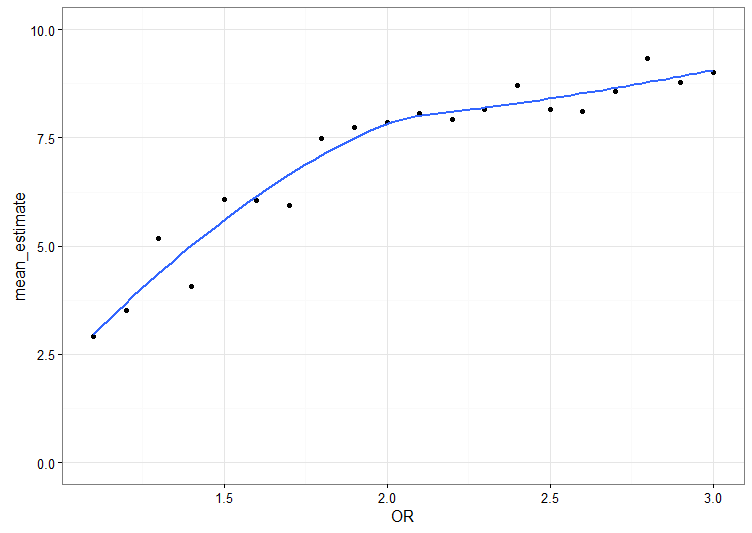
In the last post about conceptions of data-driven science, I wrote about the idea that reality is so complicated that we might need computers to help us reason about it. To be fair, even simple relationships in small data are too much for our puny brains to handle intuitively. We need to do the calculations. Here is Guest & Martin’s Pizza Problem of scientific reasoning, as presented in a thread by @cretiredroy on Twitter:
I ordered a 9-inch Pizza.
After a while, the waiter brought two 5-inch pizzas and said, the 9-inch pizza was not available and he was giving me two 5-inches Pizzas instead, and that I am getting 1 inch more for free!
The area of a circle is pi times the square of the radius r. A number n of 5-inch pizzas is smaller than a 9-inch pizza if:

Which we can rearrange to:

@cretiredroy again:
I said that even if he gave three pizzas, I would still lose-out.
”How can you say you are giving me an extra inch for free?”
The owner was speechless.
He finally gave me 4 pizzas.Take Maths seriously!
Guest & Martin (2021) use this simple problem as their illustration for computational model building: two 5 inch pizzas for the same price as one 9 inch pizza is not a good deal, because the 9 inch pizza contains more food. As I said before, I don’t think in inches and Swedish pizzas usually come in only one size, but this is counterintuitive to many people who have intuitions about inches and pizzas.
(In Guest & Martin's paper, the numbers are actually 12 and 18 inches. We can generalise to any radiuses of big and small pizzas:

Plugging in 12 and 18 gives 2.25, meaning that three 12-inch pizzas would be needed to sweeten the deal.)
We assume that we already agree that the relevant quantity is the area of pizza that we get. If we were out to optimise the amount of crust maybe the circumference, which is 2 times pi times the radius r, would be more relevant. In that case:


And the two smaller pizzas are a better deal with respect to crust circumference.
The risk of inconsistencies in our scientific understanding because we cannot intuitively grasp the implications of our models is what Guest & Martin call "The pizza problem". They believe that it can be ameliorated by computational modelling. If we have to make the calculations, we will notice and have to deal with assumptions we would otherwise not think about.
This is a different benefit of doing the calculations than the intuition building I wrote about in my post about the Monty Hall problem:
The outcome of the simulation is less important than the feeling that came over me as I was running it, though. As I was taking on the role of the host and preparing to take away one of the losing options, it started feeling self-evident that the important thing is whether the first choice is right. If the first choice is right, holding is the right strategy. If the first choice is wrong, switching is the right option. And the first choice, clearly, is only right 1/3 of the time.
I don’t think anyone is saying that it is impossible to intuitively grasp the case of the pizza deals. If you are used to relationships with squares, you might do it as quickly as @cretiredroy in the Twitter thread. However, because even simple power law relationships and probability experiments are tricky for us to reason about when we are naive to them, that should give us pause about our ability to reason verbally about new causal patterns. We might need some help.
Guest & Martin use the pizza example to illustrate their model of science as a hierarchy of frameworks, theories, specifications, implementations, hypotheses and data. The "framework" contains concepts of pizza, food and order, leading to the idea to maximize the amount of food per order. Our decision to care about amount of pizza and not about crust circumference belongs here. They describe two competing "theories": one that we need to maximise surface area and one that we need to maximise number of pizzas. The specification is the model of the area of a circle, and the implementation is plugging the numbers into it.
They argue that the "theory", "specification" and "implementation" steps are often omitted, and that doing so (prematurely jumping on to data collection), leads to inconsistencies that could have been avoided by being explicit about these steps. That is, in the pizza case, one should first write down the equations for the surface area of pizzas and compute the results before ordering the two deals and weighing the pizzas.
Just writing down the equations is not enough. In their talk on the topic for Glasgow ReproducibiliTea, Guest & Martin (2020) emphasise that the pizza problem is an issue even when we already have a formal model that describes the problem well — as in the pizza case, everyone agrees on the maths of the area of a circle — but that does not prevent the result from being counterintuitive. The formal model does not actually help resolve the confusion until it is used to compute the area of the two pizza orders.



I wanted to illustrate this post with a photo of a pizza from the chippy in Penicuik, where you get a complimentary box of chips with the larger size pizza, but I couldn’t find it. Instead, here are some pizzas from #GeneticistsTweetingAboutPizza.
References
@cretiredroy Twitter thread https://twitter.com/cretiredroy/status/1542351846903529472
Guest, O., & Martin, A. E. (2021). How computational modeling can force theory building in psychological science. Perspectives on Psychological Science, 16(4), 789-802.
Guest O & Martin (2020). How computational modeling can force theory building in psychological science (Glasgow ReproTea). Recording. https://www.youtube.com/watch?v=_WV7EFvFAB8