Alla vet att stickprovsstorlek spelar roll: stora undersökningar och experiment är i allmänhet trovärdigare än små. Frågan är bara: hur stora och hur trovärdiga? I den förra posten skrev jag lite om klassiska styrkeberäkningar och tog som exempel en studie av Raison m. fl. om antiinflammatoriska antikroppar mot depression. (Spoiler: det verkar inte ha någon större effekt.) Nyss såg jag en kort förhandspublicerad artikel av Andrew Gelman och John Carlin som utvecklar ett lite annat sätt att se på styrka — eller designanalys, som de skriver — med två nya mått på studiers dålighet. Föreställ dig ett experiment som fungerar ungefär som det med antikropparna: två grupper av deprimerade patienter får en ny medicin (här: antikroppen infliximab) eller placebo, och det som intresserar oss är skillnaden mellan grupperna är efter en tids behandling.
I klassiska styrkeberäkningar handlar det om kontrollera risken att göra så kallat typ 2-fel, vilket betyder att missa en faktisk skillnad mellan grupperna. Typ 1-fel är att råka se en skillnad som egentligen inte finns där. Det här sättet att resonera har Gelman inte mycket till övers för. Han (och många andra) brukar skriva att vi oftast redan vet redan från början att skillnaden inte är noll: det vi behöver veta är inte om det finns en skillnad mellan de som fått infliximab och de andra, utan i vilken riktning skillnaden går — är patienterna som blivit behandlade friskare eller sjukare? — och ifall skillnaden är stor nog att vara trovärdig och betydelsefull.
Därför föreslår Gelman & Carlin att vi ska titta på två andra typer av fel, som de kallar typ S, teckenfel, och typ M, magnitudfel. Teckenfel är att säga att skillnaden går åt ena hållet när den i själva verket går åt det andra. Magnitudfel är att säga att en skillnad är stor när den i själva verket är liten — Gelman & Carlin mäter magnitudfel med en exaggeration factor, som är den skattade skillnaden i de fall där det är stort nog att anses signifikant skild från noll dividerat med den verkliga skillnaden.
Låt oss ta exemplet med infliximab och depression igen. Gelman & Carlin understryker hur viktigt det är att inte ta sina antaganden om effektstorlek ur luften, så jag har letat upp några artiklar som är sammanställningar av många studier av antidepressiva mediciner. Om vi antar att utgångsläget är 24 enheter på Hamiltons depressionsskala (vilket är ungefär vad patienterna hade i början av experimentet) motsvarar medeleffekten i Kahn & cos systematiska litteraturstudie en skillnad på 2.4 enheter. Det överensstämmer ganska väl med Gibbons & cos metaanalys av fluoxetine and venlafaxine där skillnaden överlag var 2.6 enheter. Storosum & cos metaanalys av tricykliska antidepressiva medel har en skillnad på 2.8 enheter. Det är såklart omöjligt att veta hur stor effekt infliximab skulle ha ifall det fungerar, men det verkar väl rimligt att anta något i samma storleksordning som fungerande mediciner? I antikroppsstudiens styrkeberäkning kom de fram till att de borde ha en god chans att detektera en skillnad på 5 enheter. Den uppskattningen verkar ha varit ganska optimistisk.
Precis som med den första styrkeberäkningen så har jag gjort simuleringar. Jag har prövat skillnader på 1 till 5 enheter. Det är 60 deltagare i varje grupp, precis som i experimentet, och samma variation som författarna använt till sin styrkeberäkning. Jag låter datorn slumpa fram påhittade datamängder med de parametrarna och sedan är det bara att räkna ut risken för teckenfel och överskattningsfaktorn.
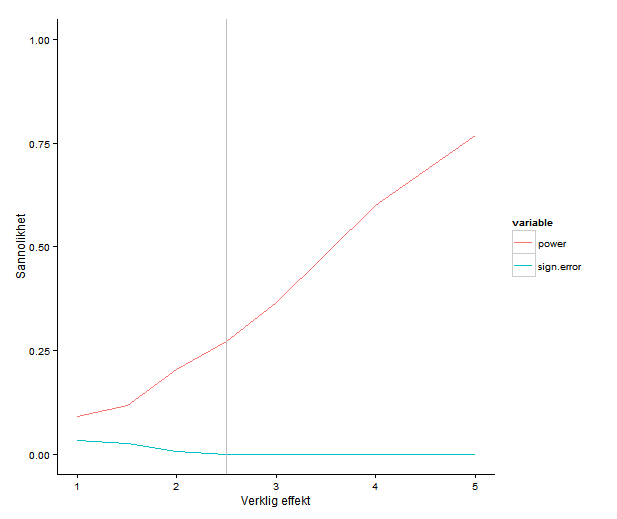
Det här diagrammet visar chansen att få ett signifikant resultat (alltså styrkan) samt risken för teckenfel vid olika verkliga effektstorlekar. Den grå linjen markerar 2.5 enheter. Jämfört med Gelmans & Carlins exempel ser risken för teckenfel inte så farlig ut: den är väldigt nära noll vid realistiska effekter. Styrkan är fortfarande sådär, knappa 30% för en effekt på 2.5 enheter.
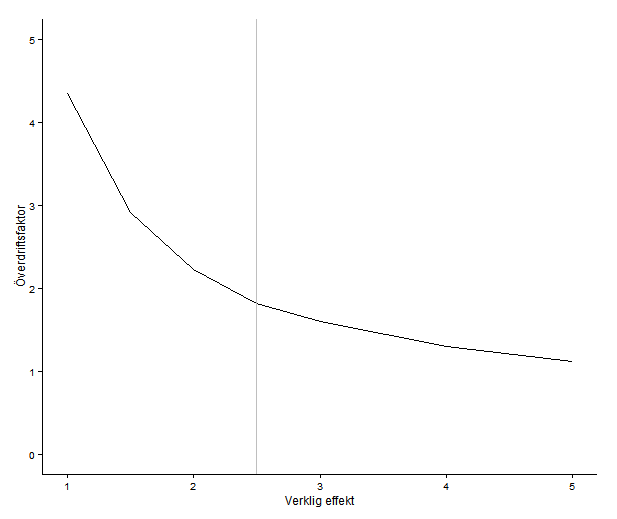
Det här diagrammet är överskattningsfaktorn vid olika effektstorlekar — jag försökte demonstrerar samma sak med histogram i förra posten. Vid 5 enheter, som är den effektstorlek författarna räknat med, har kurvan hunnit plana ut nära ett, alltså ingen större överskattning. Men vid 2.5 får vi ändå räkna med att skillnaden ser ut att vara dubbelt så stor som den är. Sammanfattningsvis: författarna bör kunna utesluta stora effekter som fem enheter på Hamiltonskalan, men dagens antidepressiva mediciner verkar ha betydligt mindre effekt än så. Alltså finns det risk att missa realistiska effekter och ännu värre blir det förstås när de börjar dela upp försöket i mindre undergrupper.
Litteratur
Gelman A & Carlin J (2013) Design analysis, prospective or retrospective, using external information. Manuskript på Gelmans hemsida.
Storosum JG, Elferink AJA, van Zwieten BJ, van den Brink W, Gersons BPR, van Strik R, Broekmans AW (2001) Short-term efficacy of tricyclic antidepressants revisited: a meta-analytic study European Neuropsychopharmacology 11 pp. 173-180 http://dx.doi.org/10.1016/S0924-977X(01)00083-9.
Gibbons RD, Hur K, Brown CH, Davis JM, Mann JJ (2012) Benefits From Antidepressants. Synthesis of 6-Week Patient-Level Outcomes From Double-blind Placebo-Controlled Randomized Trials of Fluoxetine and Venlafaxine. Archives of General Psychiatry 69 pp. 572-579 doi:10.1001/archgenpsychiatry.2011.2044
Khan A, Faucett J, Lichtenberg P, Kirsch I, Brown WA (2012) A Systematic Review of Comparative Efficacy of Treatments and Controls for Depression. PLoS ONE e41778 doi:10.1371/journal.pone.0041778
Raison CL, Rutherford RE, Woolwine BJ, Shuo C, Schettler P, Drake DF, Haroon E, Miller AH (2013) A Randomized Controlled Trial of the Tumor Necrosis Factor Antagonist Infliximab for Treatment-Resistant Depression. JAMA Psychiatry 70 pp. 31-41. doi:10.1001/2013.jamapsychiatry.4
Kod
Gelman & Carlin skriver om en R-funktion för felberäkningarna, men jag hittar den inte. För min simulering, se github.

Pingback: Åtminstone tre sorters osäkerhet | There is grandeur in this view of life