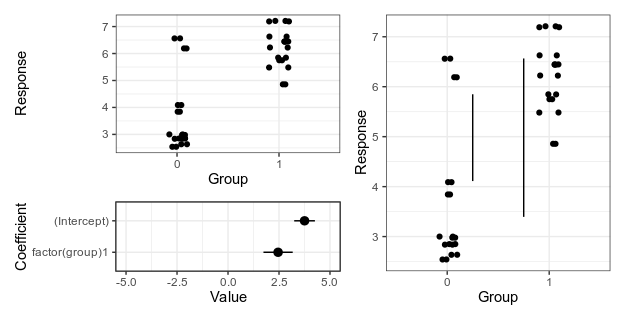
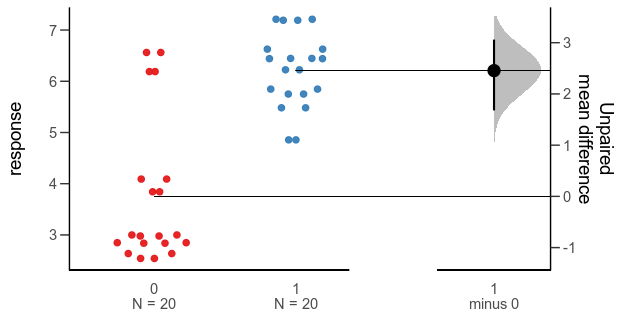
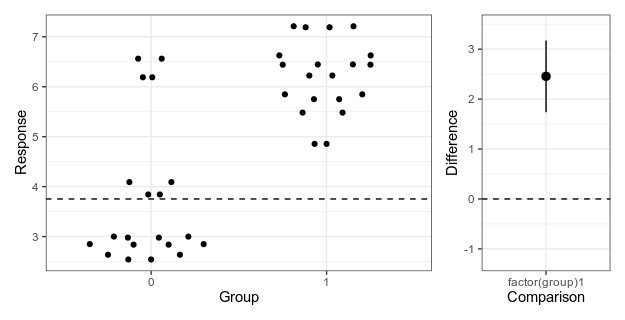
Like many others, I’ve never felt that the solution to the Monty Hall problem was intuitive, despite the fact that explanations of the correct solution are everywhere. I am not alone. Famously, columnist Marilyn vos Savant got droves of mail from people trying to school her after she had published the correct solution.
The problem goes like this: You are a contestant on a game show (based on a real game show hosted by Monty Hall, hence the name). The host presents you with three doors, one of which contains a prize — say, a goat — and the others are empty. After you’ve made your choice, the host opens one of the doors, showing that it is empty. You are now asked whether you would like to stick to your initial choice, or switch to the other door. The right thing to do is to switch, which gives you 2/3 probability of winning the goat. This can be demonstrated in a few different ways.

A goat is a great prize. Image: Casey Goat by Pete Markham (CC BY-SA 2.0)
So I sat down to do 20 physical Monty Hall simulations on paper. I shuffled three cards with the options, picked one, and then, playing the role of the host, took away one losing option, and noted down if switching or holding on to the first choice would have been the right thing to do. The results came out 13 out of 20 (65%) wins for the switching strategy, and 7 out of 20 (35%) for the holding strategy. Of course, the Monty Hall Truthers out there must question whether this demonstration in fact happened — it’s too perfect, isn’t it?

The outcome of the simulation is less important than the feeling that came over me as I was running it, though. As I was taking on the role of the host and preparing to take away one of the losing options, it started feeling self-evident that the important thing is whether the first choice is right. If the first choice is right, holding is the right strategy. If the first choice is wrong, switching is the right option. And the first choice, clearly, is only right 1/3 of the time.
In this case, it was helpful to take the game show host’s perspective. Selvin (1975) discussed the solution to the problem in The American Statistician, and included a quote from Monty Hall himself:
Monty Hall wrote and expressed that he was not ”a student of statistics problems” but ”the big hole in your argument is that once the first box is seen to be empty, the contestant cannot exchange his box.” He continues to say, ”Oh, and incidentally, after one [box] is seen to be empty, his chances are no longer 50/50 but remain what they were in the first place, one out of three. It just seems to the contestant that one box having been eliminated, he stands a better chance. Not so.” I could not have said it better myself.
A generalised problem
Now, imagine the same problem with a number d number of doors, w number of prizes and o number of losing doors that are opened after the first choice is made. We assume that the losing doors are opened at random, and that switching entails picking one of the remaining doors at random. What is the probability of winning with the switching strategy?
The probability of picking the a door with or without a prize is:
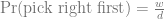

If we picked a right door first, we have w – 1 winning options left out of d – o – 1 doors after the host opens o doors:
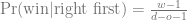
If we picked the wrong door first, we have all the winning options left:
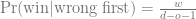
Putting it all together:

As before, for the hold strategy, the probability of winning is the probability of getting it right the first time:
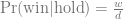
With the original Monty Hall problem, w = 1, d = 3 and o = 1, and therefore

Selvin (1975) also present a generalisation due to Ferguson, where there are n options and p doors that are opened after the choice. That is, w = 1, d = 3 and o = 1. Therefore,
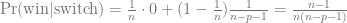
which is Ferguson’s formula.
Finally, in Marilyn vos Savant’s column, she used this thought experiment to illustrate why switching is the right thing to do:
Here’s a good way to visualize what happened. Suppose there are a million doors, and you pick door #1. Then the host, who knows what’s behind the doors and will always avoid the one with the prize, opens them all except door #777,777. You’d switch to that door pretty fast, wouldn’t you?
That is, w = 1 still, d = 106 and o = 106 – 2.
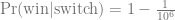
It turns out that the solution to the generalised problem is that it is always better to switch, as long as there is a prize, and as long as the host opens any doors. One can also generalise it to choosing sets of more than one door. This makes some intuitive sense: as long as the host takes opens some doors, taking away losing options, switching should enrich for prizes.
Some code
To be frank, I’m not sure I have convinced myself of the solution to the generalised problem yet. However, using the code below, I did try the calculation for all combinations of total number of doors, prizes and doors opened up to 100, and in all cases, switching wins. That inspires some confidence, should I end up on a small ruminant game show.
The code below first defines a wrapper around R’s sampling function, which has a very annoying alternative behaviour when fed a vector of length one, to be able to build a computational version of my physical simulation. Finally, we have a function for the above formulae. (See whole thing on GitHub if you are interested.)
## Wrap sample into a function that avoids the "convenience"
## behaviour that happens when the length of x is one
sample_safer <- function(to_sample, n) {
assert_that(n <= length(to_sample))
if (length(to_sample) == 1)
return(to_sample)
else {
return(sample(to_sample, n))
}
}
## Simulate a generalised Monty Hall situation with
## w prizes, d doors and o doors that are opened.
sim_choice <- function(w, d, o) {
## There has to be less prizes than unopened doors
assert_that(w < d - o)
wins <- rep(1, w)
losses <- rep(0, d - w)
doors <- c(wins, losses)
## Pick a door
choice <- sample_safer(1:d, 1)
## Doors that can be opened
to_open_from <- which(doors == 0)
## Chosen door can't be opened
to_open_from <- to_open_from[to_open_from != choice]
## Doors to open
to_open <- sample_safer(to_open_from, o)
## Switch to one of the remaining doors
possible_switches <- setdiff(1:d, c(to_open, choice))
choice_after_switch <- sample_safer(possible_switches , 1)
result_hold <- doors[choice]
result_switch <- doors[choice_after_switch]
c(result_hold,
result_switch)
}
## Formulas for probabilities
mh_formula <- function(w, d, o) {
## There has to be less prizes than unopened doors
assert_that(w < d - o)
p_win_switch <- w/d * (w - 1)/(d - o - 1) +
(1 - w/d) * w / (d - o - 1)
p_win_hold <- w/d
c(p_win_hold,
p_win_switch)
}
## Standard Monty Hall
mh <- replicate(1000, sim_choice(1, 3, 1))
> mh_formula(1, 3, 1) [1] 0.3333333 0.6666667 > rowSums(mh)/ncol(mh) [1] 0.347 0.653
The Monty Hall problem problem
Guest & Martin (2020) use this simple problem as their illustration for computational model building: two 12 inch pizzas for the same price as one 18 inch pizza is not a good deal, because the 18 inch pizza contains more food. Apparently this is counter-intuitive to many people who have intuitions about inches and pizzas.
They call the risk of having inconsistencies in our scientific understanding because we cannot intuitively grasp the implications of our models ”The pizza problem”, arguing that it can be ameliorated by computational modelling, which forces you to spell out implicit assumptions and also makes you actually run the numbers. Having a formal model of areas of circles doesn’t help much, unless you plug in the numbers.
The Monty Hall problem problem is the pizza problem with a vengeance; not only is it hard to intuitively grasp what is going on in the problem, but even when presented with compelling evidence, the mental resistance might still remain and lead people to write angry letters and tweets.
Literature
Guest, O, & Martin, AE (2020). How computational modeling can force theory building in psychological science. Preprint.
Selvin, S (1975) On the Monty Hall problem. The American Statistician 29:3 p.134.