Häromveckan skrev jag något kritiskt om vetenskap i medier. Det gör jag inte så ofta längre.
Det var en post om genetisk variation i MAOA-genen som kopplats till antisocialt beteende (med mera med mera) och dokumentären ”Ditt förutbestämda liv” som SVT sände ganska nyligen. Den går inte att se på SVT Play längre, men det finns en trailer i alla fall.
En gång i tiden så brukade jag läsa DN:s och SR:s vetenskapssidor och om jag hittade något intressant slå upp originalartiklarna, leta reda på pressmeddelanden, artiklar i engelskspråkiga tidningar som stått som förebild och så vidare. Ibland skrev jag kritiska brev och ibland postade jag länkar till originalartiklar, så de plockades upp av någon aggregator och länkades från nyhetsartikeln. Det var oskyldigare webbtider när nyhetstidningar var villiga att länka ogranskade bloggposter från sina artiklar. Men jag har nästan slutat med det, och när jag skriver något kritiskt gör det mig alltid lite nervös. Det är av flera anledningar:
1. Är det så viktigt att det är rätt?
Jag har förstås skaffat mig en massa onödigt bestämda åsikter om genetik, evolution och hur man bör uttrycka sig om dem. Det vore onödigt att tjafsa om alla dessa småsaker. Men jag tycker ändå att det är rimligt att kritisera beskrivningar av forskning som säger saker som inte är sanning, till exempel att ett par kandidatgenstudier från 2002-2003 är banbrytande och skriver om hela genetiken, eller att genetisk variation i MAOA är viktig för att förstå antisocialt beteende, när bevisen för det är i högsta grad skakiga. Dokumentären påstod till och med att Caspi et al 2003 (den om depression och serotonintransportgenen 5HTT) skulle vara en av världens mest refererade artiklar.
2. Tänk om jag har fel?
Det har jag ju ändå rätt ofta. Det finns en hel litteratur om MAOA, något tjog primärstudier eller så. De är, som jag skrev, en blandad kompott av positiva och negativa resultat (Foley & al 2004, Huang & al 2004, Haberstick & al 2005, Huizinga & al 2006, Kim-Cohen & al 2006, Nilsson & al 2006, Widom, Spatz & Brzustowicz 2006, Young & al 2006, Frazzetto & al 2007, Rief & al 2007, van der Vegt & al 2009, Weder & al 2009, Beach & al 2010, Derringer & al 2010, Edwards & al 2010, Enoch & al 2010). Det tyder på att effekten är för liten eller för variabel i förhållande till stickprovsstorleken. Knäckfrågan i det här fallet, som behövs för att kunna utvärdera både originalstudien och uppföljarna är: Om det nu skulle finnas en interaktion mellan varianter av MAOA och en dålig uppväxt, hur stor skulle den vara då? Tyvärr är det inte så lätt att veta.
Om vi skulle försöka oss på att rita en styrkekurva för interaktionen mellan MAOA och dålig uppväxt (Caspi & al 2002), det vill säga hur stor sannolikhet en studie av den här storleken har att hitta en effekt, så måste vi gissa vad en realistisk effekt skulle kunna vara. Artikeln gör en rad jämförelser, men om vi ska välja en så tycker jag det är rimligt att ta skillnaden mellan de som har riskvarianter och som inte blivit illa behandlade och de som har den och har blivit gravt illa behandlade under uppväxten. Om riskvarianter av MAOA verkligen gör människor mer sårbara för att bli illa behandlade under barndomen, så borde den här jämförelsen visa det. Vi behöver också välja en av variablerna att koncentrera oss på. Varför inte uppförandestörning (conduct disorder), vilket måste vara den som nämns i dokumentären.
Om vi simulerar data med olika oddskvoter (x-axeln; OR står för ”odds ratio”) och ritar en styrkekurva blir resultatet ungefär så här. (Obs, jag har läst av siffrorna från ett av diagrammen i artikeln. De är nog bara ungefär rätt.) Det vill säga, om vi antar samma andel ”gravt illa behandlade” individer och samma stickprovsstorlek, så ökar sannolikheten att hitta ett statistiskt signifikant resultat ungefär så här:
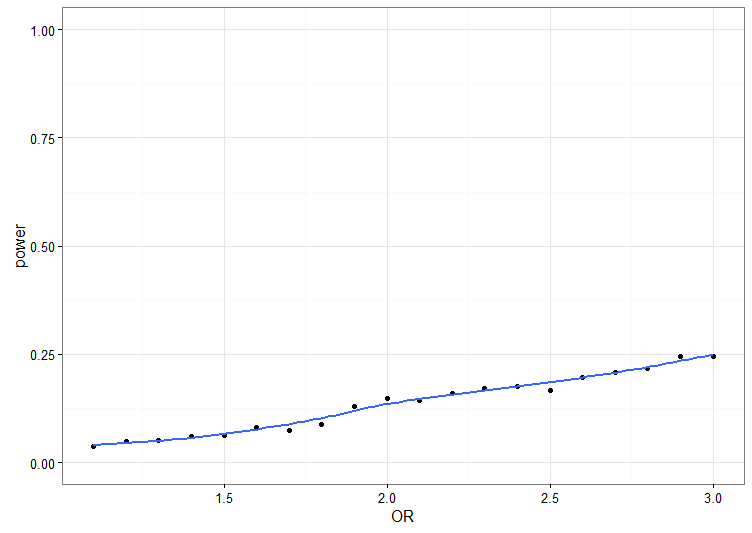
Det vill säga, den är inte särskilt stor. Vilka effektstorlekar kan vara rimliga? I samma artikel skattar de oddskvoten kopplad till att bli illa behandlad (hos de utan riskvarianten, och de är betydligt fler) till 2.5 för gravt illa behandlade och 1.3 för ”sannolikt” illa behandlade. Ficks & Waldman (2013) gjorde en metaanalys av studier med MAOA och antisocialt beteende (utan att ta hänsyn till interaktioner) och fick en oddskvot på 1.2. Rautiainen et al (2016) har gjort en helgenomsanalys av aggression hos vuxna och den största effekt de hittar är ungefär 2.2.
Men problemet med låg styrka är inte bara att det är svårt att få ett statistiskt signifikant resultat om det finns en stor och riktig skillnad. För om man, mot alla odds, hittar ett statistiskt signifikant resultat, hur stor ser effekten ut att vara? Den ser, med nödvändighet, ut att vara jättestor. Det här diagrammet visar den skattade effekten i simuleringar där resultatet var statistiskt signifikant (på 5%-nivån):
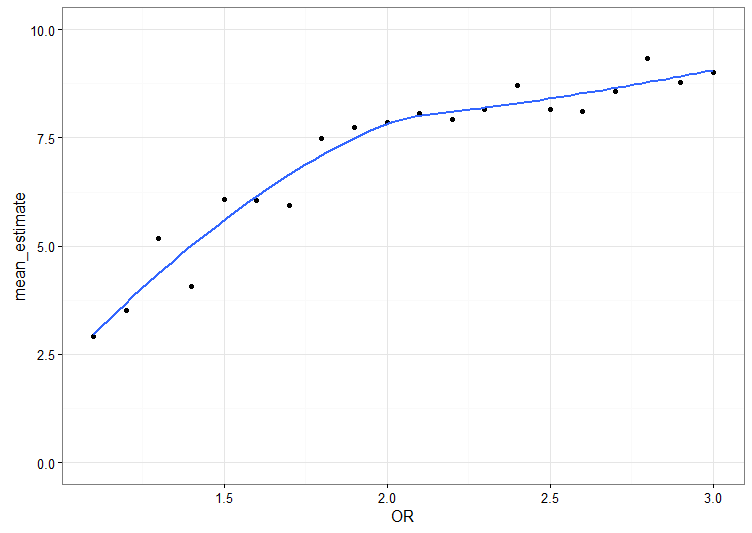
Men visst, det är förstås möjligt att de ursprungliga studierna hade tur med sina handfullar människor, att de som misslyckades med att detektera någon interaktion hade otur, och att MAOA-varianter kommer visa sig ha stora reproducerbara effekter när det efter hand börjar komma helgenomstudier som inkluderar interaktioner med miljövariabler. Jag håller inte andan.
(Koden bakom diagrammen finns på github. Förutom osäkerheten om vilken jämförelse som är den mest relevanta, så beror styrkan hos logistisk regression också på den konstanta termen, oddsen för beteendeproblem hos de som saknar riskvarianten. De är något fler än de som har den, men det är ändå en skattning med stor osäkerhet. Här har jag bara stoppat in den skattning jag fått ur data utläst ur diagrammet i Caspi & co 2002.)
3. Vill jag verkligen ha rollen som den professionella gnällspiken?
”Det finns en i varje familj. Två i min faktiskt.” Och det finns minst en på varje vetenskaplig konferens, i varje hörn av den vetenskapliga litteraturen, och på vetenskapsbloggar här och där … Alltså, någon som gjort det till sin uppgift att protestera, gärna med hög röst och blommigt språk, varje gång någon inte gör någon viss vetenskaplig idé rättvisa. Det finns förstås ett värde i kritik, och ingen har någon plikt att komma med ett bättre alternativ när de framför välgrundad kritik. Men det är ändå inte den skojigaste rollen, och det är inte riktigt vad jag vill viga mitt liv åt.
Så, varför inte skriva om något med arv och miljö som jag gillar? Här är en artikel jag såg publiceras ganska nyligen om förhållandet mellan arv, miljö och risk — i det här fallet handlar det om hjärtsjukdom.
Khera, Amit V., et al. ”Genetic Risk, Adherence to a Healthy Lifestyle, and Coronary Disease.” New England Journal of Medicine (2016).
Den här studien vinner, ur mitt perspektiv, på att den inte bara koncentrerar sig på en enda gen, utan kombinerar information från varianter av ett gäng (femtio) gener där varianter tidigare kopplats till risk för hjärtsjukdom. När det gäller komplexa egenskaper som påverkas av många genetiska varianter är det här en mycket bättre idé. Det är antagligen till och med en nödvändighet för att dra några meningsfulla slutsatser om genetisk risk. De kombinerar också ett antal miljövariabler som antas påverka risken för hjärtsjukdom, det vill säga mer eller mindre hälsosamma vanor.
(Artikeln är tillgänglig gratis men inte licensierad under någon rimlig licens, så jag visar inte det diagram från artikeln jag skulle vilja visa här. Klicka på länken och titta på ”Figure 3” om du vill se det.)
Själva sensmoralen i ”Ditt förutbestämda liv” var att gener i och för sig spelar roll, men att en bra uppväxt är bra för alla. Det kan i och för sig gömma sig gen–miljöinteraktioner under de additiva effekter som den här studien bygger på, men sensmoralen blir ändå densamma: ett hälsosamt leverne verkar vara bra för alla, även de som haft otur med sina genetiska varianter och fått hög genetisk risk.
4. Det känns orättvist mot de som försökt kommunicera vetenskap, och kanske kontraproduktivt.
Tack och lov behöver jag sällan skriva om saker som är särskilt långt ifrån det jag är utbildad inom. Vetenskapsjournalister och -reportrar gör det desto oftare, och dessutom på begränsad tid. Oftast gäller det dessutom forskning som är alldeles ny, och därför extra svår att utvärdera. Men i det här fallet gäller det faktiskt forskning som är över tio år gammal, och både de som gjorde dokumentären och Vetenskapens värld som valde dess inramning i SVT misslyckades helt, tycker jag, med att sätta den i perspektiv. Jag vet inte om det är författarna själva eller dokumentärmakarna som är orsak till att vinkeln var enastående genombrott som inte behöver ifrågasättas eller nyanseras. Kanske är det orättvist att kräva av Vetenskapens värld-redaktionen att de ska anlägga ett annat perspektiv än dokumentären de valt att sända. Eftersom att jag gärna vill vill att reportrar och journalister ska skriva entusiastiskt om genetisk forskning (inklusive helst min egen), så tvekar jag lite att skriva ner dem med arga brev. Förhoppningsvis tar de inte allt för illa upp.
Litteratur
Ficks, Courtney A., and Irwin D. Waldman. ”Candidate genes for aggression and antisocial behavior: a meta-analysis of association studies of the 5HTTLPR and MAOA-uVNTR.” Behavior genetics 44.5 (2014): 427-444.
Rautiainen, M. R., et al. ”Genome-wide association study of antisocial personality disorder.” Translational Psychiatry 6.9 (2016): e883.
Khera, Amit V., et al. ”Genetic Risk, Adherence to a Healthy Lifestyle, and Coronary Disease.” New England Journal of Medicine (2016).
(Samt en massa kandidatgenstudier om MAOA som jag länkar ovan.)







