Yesterday, 29 Feburary 2020, was the 20th anniversary of the release R 1.0.0. Jozef Hajnala’s blog has a cute anniversary post with some trivia. I realised that it is also (not to the day, but to the year) my R anniversary.
I started using R in 2010, during my MSc project in Linköping. Daniel Nätt, who was a PhD student there at the time, was using it for gene expression and DNA methylation work. I think that was the reason he was pulled into R; he needed the Bioconductor packages for microarrays. He introduced me. Thanks, Daniel!
I think I must first have used it to do something with qPCR melting curves. I remember that I wrote some function to reshape/pivot data between long and wide format. It was probably an atrocity of nested loops and hard bracket indexing. Coming right from an undergraduate programme with courses using Ada and C++, even if we had also used Minitab for statistics and Matlab for engineering, I spoke R with a strong accent. At any rate, I was primed to think that doing my data analysis with code was a good idea, and jumped at the opportunity to learn a tool for it. Thanks, undergraduate programme!
I think the easiest thing to love about R is the package system. You can certainly end up in dependency hell with R and metaphorically shoot your own foot, especially on a shared high performance computing system. But I wouldn’t run into any of that until after several years. I was, and still am, impressed by how packages just worked, and could do almost anything. So, the Bioconductor packages were probably, indirectly, why I was introduced to R, and after that, my R story can be told in a series of packages. Thanks, CRAN!
The next package was R/qtl, that I relied on for my PhD. I had my own copy of the R/qtl book. For a period, I probably wrote thing every day:
library(qtl) cross <- read.cross(file = "F8_geno_trim.csv", format = "csv")
R/qtl is one of my favourite pieces or research software, relatively friendly and with lots of documentation. Thanks, R/qtl developers!
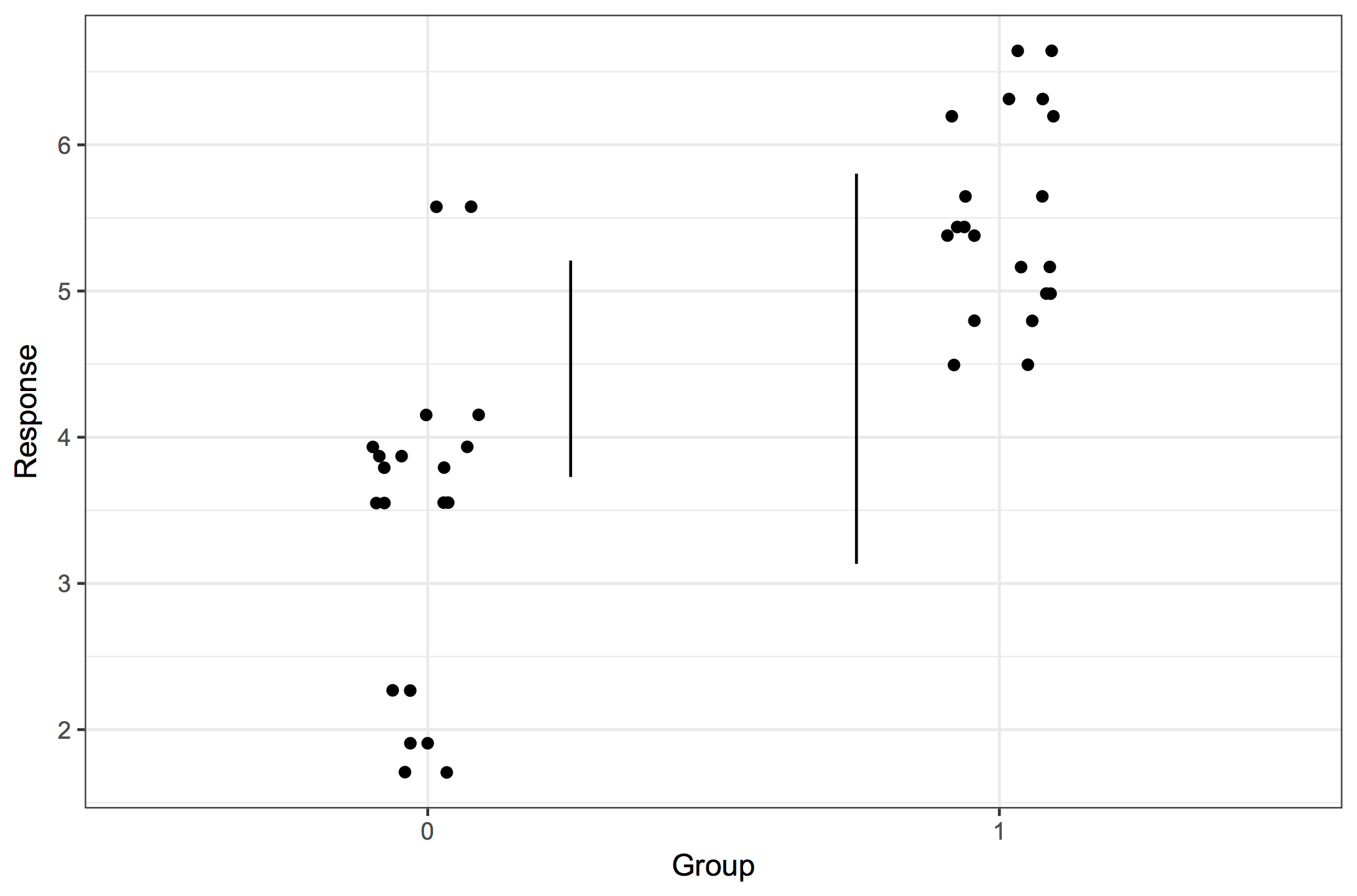
Of course it was Dom Wright, who was my PhD supervisor, who introduced me to R/qtl, and I think it was also he who introduced me to ggplot2. At least he used it, and at some point we were together trying to fix the formatting of a graph, probably with some ugly hack. I decided to use ggplot2 as much as possible, and as it is wont to, ggplot2 made me care about rearranging data, thus leading to reshape2 and plyr. ”The magic is not in plotting the data but in tidying and rearranging the data for plotting.” After a while, most everything I wrote used the ddply function in some way. Thank you, Hadley Wickham!
Then came the contemporary tidyverse. For the longest time, I was uneasy with tidyr, and I’m still not a regular purrr user, but one can’t avoid loving dplyr. How much? My talk at the Swedish Bioinformatics Workshop in 2016 had a slide expressing my love of the filter function. It did not receive the cheers that the function deserves. Maybe the audience were Python users. With new file reading functions, new data frames and functions to manipulate data frames, modern R has become smoother and friendlier. Thanks, tidyverse developers!
The history of R on this blog started in 2011, originally as a way to make notes for myself or, ”a fellow user who’s trying to google his or her way to a solution”. This turned into a series of things to help teach R to biologists around me.
There was the Slightly different introduction to R series of blog posts. It used packages that feel somewhat outdated, and today, I don’t think there’s anything even slightly different about advocating RStudio, and teaching ggplot2 from the beginning.
This spawned a couple of seminars in course for PhD students, which were updated for the Wright lab computation lunches, and eventually turned into a course of its own given in 2017. It would be fun to update it and give it again.
The last few years, I’ve been using R for reasonably large genome datasets in a HPC environment, and gotten back to the beginnings, I guess, by using Bioconducor a lot more. However, the package that I think epitomises the last years of my R use is AlphaSimR, developed by colleagues in Edinburgh. It’s great to be able throw together a quick simulation to check how some feature of genetics behaves. AlphaSimR itself is also an example of how far the R/C++ integration has come with RCpp and RCppArmadillo. Thanks, Chris!
In summary, R is my tool of choice for almost anything. I hope we’ll still be using it, in new and interesting ways, in another ten years. Thank you, R core team!