1. Imre Lakatos, Science and pseudoscience
Vetenskapsfilosofi är något folk i allmänhet, och jag själv i synnerhet, borde läsa mer av och tänka mer på. Svårt verkar det också — trots käcka bilder och Richard Feynman-citat. Imre Lakatos var en vetenskapsfilosof vars namn jag stött på här och där, men inte läst något av förrän alldeles nyligen. Via Dynamic Ecology hittade jag en länk till ett av hans föredrag:
As opposed to Popper the methodology of scientific research programmes does not offer instant rationality. One must treat budding programmes leniently: programmes may take decades before they get off the ground and become empirically progressive. Criticism is not a Popperian quick kill, by refutation. Important criticism is always constructive: there is no refutation without a better theory. Kuhn is wrong in thinking that scientific revolutions are sudden, irrational changes in vision. … On close inspection both Popperian crucial experiments and Kuhnian revolutions turn out to be myths: what normally happens is that progressive research programmes replace degenerating ones.
2. Trudy Mackay, The genetic architecture of quantitative traits
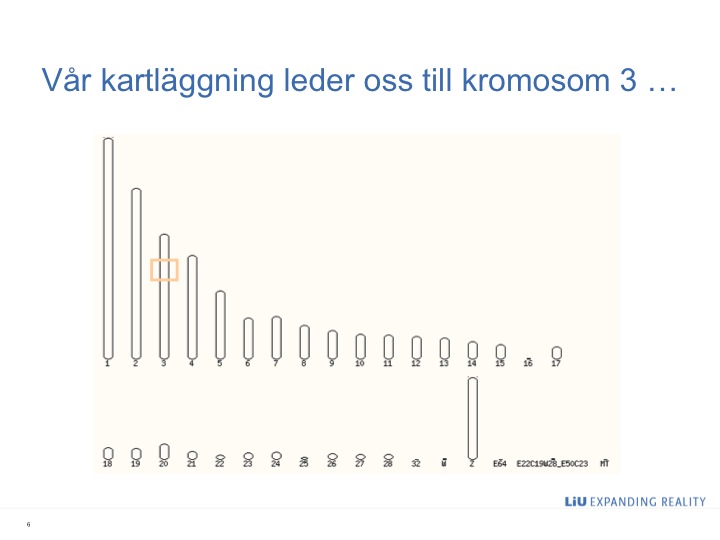
Jag var på ESEB-konferensen i Lissabon i somras och det var helt fantastiskt på snart sagt alla sätt (mitt glada jollrande om konferensen finns här och här). Bland det bästa var det här föredraget från Trudy Mackay — en av dem som bokstavligen skrev boken om kvantitativ genetik. Mackay pratade om hennes grupps arbete med genetisk kartläggning av kvantitativa egenskaper i bananflugor och om gen–gen-interaktioner, som det verkar finnas förvånansvärt många av — vilket gör saker mer komplicerade och roligare. Naturligtvis blir det ganska tekniskt efter hand och presentationsbilderna är tyvärr oläsliga, men det rekommenderas ändå varmt. Dessutom börjar Mackay med en genomgång av vad kvantitativ genetik är, varför det är viktigt och varför en kan lära sig så mycket från bananflugor. Det här är ett av mina favoritcitat:
Those of you who don’t work with flies might be surprised to learn that flies vary for any phenotype that an investigator has the imagination to develop a quantitative assay for.
Några fler föredrag från konferensen har publicerats och det kommer bli fler på ESEB2013:s YouTube-kanal.
3. Richard Lenski, Telliamed Revisited
Richard Lenski är evolutionsbiolog som förmodligen är mest känd för sitt Long Term Evolution Experiment — ett evolutionsexperiment med bakterien Escherichia coli. På sin blogg skriver han bland annat om vad de hittat i det experimentet — börja till exempel med den här posten:
Fitness is the central phenotype in evolutionary theory; it integrates and encapsulates the effects of all mutations and their resulting phenotypic changes on reproductive success. Fitness depends, of course, on the environment, and here we measure fitness in the same medium and other conditions as used in the LTEE. We estimate the mean fitness of a sample from a particular population at a particular generation by competing the sample against the ancestral strain, and we distinguish them based on a neutral genetic marker. Prior to the competition, both competitors have been stored in a deep freezer, then revived, and acclimated separately for several generations before they are mixed to start the assay proper. Fitness is calculated as the ratio of their realized growth rates as the ancestor and its descendants compete head-to-head under the conditions that prevailed for 500 … or 5000 … or 50,000 generations.